Locate Each Object in Images Taken by People Who Are Blind

Overview
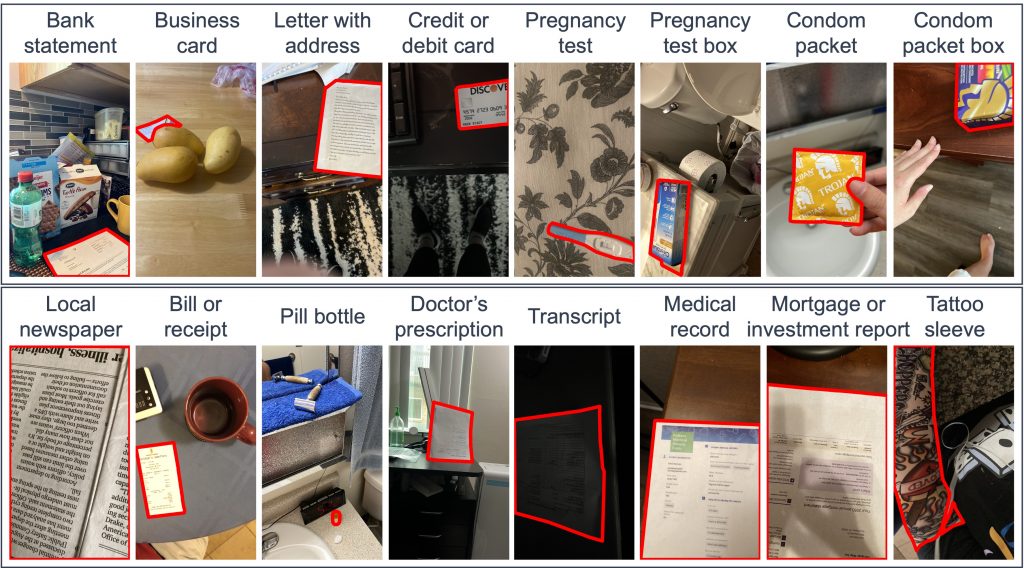
We introduce a few-shot localization dataset originating from photographers who authentically were trying to learn about the visual content in the images they took. It includes nearly 10,000 segmentations of 116 categories (100 base classes in VizWiz-FewShot and 16 novel classes in BIV-Priv-Seg) in over 5,600 images that were taken by people with visual impairments. Compared to existing few-shot object detection and instance segmentation datasets, our dataset is the first to locate holes in objects (e.g., found in 12.3% of our segmentations), it shows objects that occupy a much larger range of sizes relative to the images, and text is over five times more common in our objects (e.g., found in 22.4% of our segmentations).
Dataset
The newest version is updated on 03/19/2024.
VizWiz-FewShot (Base):
For base classes, images and annotations are included in VizWiz-FewShot dataset:
- 100 non-private categories
- 4,229 images
- 8,043 annotated instances
You may download the individual sets of components listed below.
- Base: images
- Base: annotations
BIV-Priv-Seg (Novel):
For novel classes, images and annotations are included in BIV-Priv-FewShot dataset:
- 16 private categories
- 1,072 images
- 932 annotated instances
You may download the individual sets of components listed below.
- Novel support set: images
- Novel support set: annotations
- Novel query set: images
- Novel query set: annotations

This work is licensed under a Creative Commons Attribution 4.0 International License.
Challenge
This few-shot private object detection challenge is presented and evaluated in 1-shot scenario, where VizWiz-FewShot is utilized as training set, and one object sample from each of the 16 categories in BIV-Priv-FewShot, including the annotation and the image, is provided in the support set. Given the query set, the goal is to find the 16 private objects in the images in query set. The competition is held separately for object detection and instance segmentation, where objects are localized in bounding boxes and masks, respectively.
Evaluation Metric
- Object detection: the results are evaluated in mean Average Precision (mAP). In the leaderboard, both mAP score and AP50 score are presented.
- Instance segmentation: the results are evaluated in mean Average Precision (mAP). In the leaderboard, both mAP score and AP50 score are presented.
Please find more details about the mAP metric here.
Submission Instructions
Sep 2025 update: Our evaluation servers on EvalAI are currently under transition maintenance. For offline benchmarking services, please read this page.
Submission Format
You may download the submission dummy file, query_dummy_submission.json, for reference. Below are the detailed descriptions of the submission format.
Predictions for query set should be submitted in a json file. The file should contain a list of annotations, where in each annotation, image_id indicates the image ID for this annotation, score indicates the confidence score, category_id indicates the category ID for this annotation, area indicates the area of the bounding box or the segmentation, bbox indicates the location of the bounding box in the format of [x, y, w, h], and segmentation indicates the list of segments predicted. An example of the json file for submission submission.json is below:
[
{
"image_id": 1166,
"score": 0.99,
"category_id": 115,
"area": 892803.0,
"bbox": [0, 1010, 1080, 910],
"segmentation": [
[2.0, 1089.0, 69.0, 1010.0, 489.0, 1070.0, 712.0, 1115.0, 983.0, 1157.0, 1074.0, 1168.0, 1079.0, 1914.0, 0.0, 1919.0]
]
},
{
"image_id": 10,
"score": 0.88,
"category_id": 114,
"area": 449716.5,
"bbox": [0, 524, 464, 1396],
"segmentation": [
[7.0, 540.0, 189.0, 524.0, 463.0, 1867.0, 294.0, 1913.0, 0.0, 1919.0]
]
}
]Evaluation Servers
Teams participating in the challenge must submit results for the test portion of the dataset to our evaluation servers, which are hosted on EvalAI (challenges 2024 and 2025 are deprecated). We created different partitions of the test dataset to support different evaluation purposes:
- Query-dev: This partition consists of 158 images that contain private objects to be located. Each team can upload at most 10 submissions per day to receive evaluation results.
- Query-challenge: This partition is available for a limited duration before the Computer Vision and Pattern Recognition (CVPR) conference in June 2024 to support the challenge for the few-shot private object localization task, and it contains all 1,056 images in the query set. Results on this partition will determine the challenge winners, which will be announced during the VizWiz Grand Challenge workshop hosted at CVPR. Each team can submit at most five results files over the length of the challenge and at most one result per day. The best scoring submitted result for each team will be selected as the team’s final entry for the competition.
- Query-standard: This partition is available to support algorithm evaluation year-round, and it contains all 1,056 images in the query set. Each team can submit at most five results files and at most one result per day. Each team can choose to share their results publicly or keep them private. When shared publicly, the best scoring submitted result will be published on the public leaderboard and will be selected as the team’s final entry for the competition.
For evaluation in every phase, submit results for object detection (bounding box) and instance segmentation (instances) separately as these are two separate challenges. Please find leaderboard on the EvalAI challenge page.
Rules
Members of the same team are not allowed to create multiple accounts for a single project to submit more than the maximum number of submissions permitted per team on the test-challenge and test-standard datasets. The only exception is if the person is part of a team that is publishing more than one paper describing unrelated methods.
Publications
BIV-Priv-Seg: Locating Private Content in Images Taken by People With Visual Impairments
Yu-Yun Tseng, Tanusree Sharma, Lotus Zhang, Abigale Stangl, Leah Findlater, Yang Wang, and Danna Gurari. IEEE Winter Conference on Applications of Computer Vision (WACV), 2025.
VizWiz-FewShot: Locating Objects in Images Taken by People With Visual Impairments
Yu-Yun Tseng, Alexander Bell, and Danna Gurari. European Conference on Computer Vision (ECCV), 2022.
Contact Us
For any questions about the dataset and challenge, please contact Everley Tseng at Yu-Yun.Tseng@colorado.edu.