Grounding All Answers for Each Visual Question
Overview
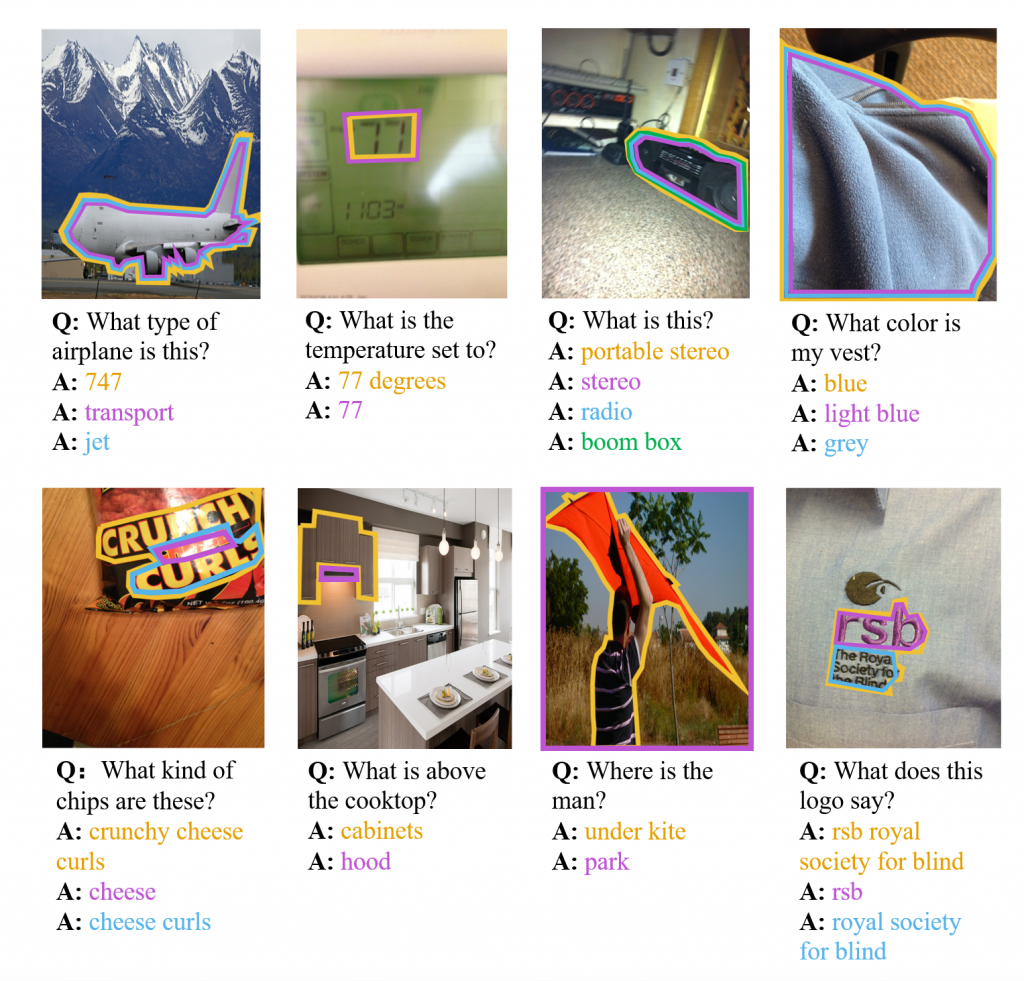
Visual Question Answering (VQA) is a task of predicting the answer to a question about an image. Given that different people can provide different answers to a visual question, we aim to better understand why with answer groundings. To achieve this goal, we introduce the VQA-AnswerTherapy dataset, the first dataset that visually grounds each unique answer to each visual question. We offer this work as a valuable foundation for improving our understanding and handling of annotator differences. This work can inform how to account for annotator differences for other related tasks such as image captioning, visual dialog, and open-domain VQA (e.g., VQAs found on Yahoo!Answers and Stack Exchange). This work also contributes to ethical AI by enabling revisiting how VQA models are developed and evaluated to consider the diversity of plausible answer groundings rather than a single (typically majority) one.
VQA-AnswerTherapy Dataset
The VQA-AnswerTherapy dataset includes:
- 3,794 training examples
- 646 validation examples
- 1,385 test examples
- Annotation download files:
- Train and validation sets annotation files [JSON files]
- Test set annotation file [JSON files]
- All crowdsourced responses from all crowd workers for every visual question (incorrect answers, no polygon, multiple polygons, answer groundings) [Raw data]
- Visual question downloads:
- VizWiz-VQA train, validation, and test
- VQAv2
- Each JSON annotation record has the following format:
{"image_id": "VizWiz_train_00012627.jpg"
"question":"what is this in front of me?",
"answers":["laptop", "keyboard"],
"height": 480,
"width": 360,
"binary_label":"single",
"grounding_labels": [[{"y": 455.71, "x": 356.8}, {"y": 4.51, "x": 236.2}, {"y": 2.59, "x": 0.0}, {"y": 477.79, "x": 2.2}, {"y": 478.75, "x": 358.6}], [{"y": 455.71, "x": 356.8}, {"y": 4.51, "x": 236.2}, {"y": 2.59, "x": 0.0}, {"y": 477.79, "x": 2.2}, {"y": 478.75, "x": 358.6}]]}answer_groundings denote all points along the boundary of the answer grounding.- You can use this [code] to evaluate a model’s prediction.

This work is licensed under a Creative Commons Attribution 4.0 International License.
Challenge
We propose a challenge designed around the aforementioned AnswerTherapy dataset to address the following task:
Task
Single Answer Grounding Challenge
Given a visual question (question-image pair), the task is to predict if a visual question will result in answers that all share the same grounding. The submissions will be evaluated based on the Precision, Recall, and F1 score. The team which achieves the maximum F1 score wins this challenge.
Submission Instructions
Sep 2025 update: Our evaluation servers on EvalAI are currently under transition maintenance. For offline benchmarking services, please read this page.
Evaluation Servers
Teams participating in the challenge must submit results for the test portion of the dataset to our evaluation servers, which are hosted on EvalAI (challenges 2024 and 2025 deprecated). We created different partitions of the test dataset to support different evaluation purposes:
- Test-dev: this partition consists of 100 test visual questions and is available year-round. Each team can upload at most 10 submissions per day to receive evaluation results.
- Test-challenge: this partition is available for a limited duration before the Computer Vision and Pattern Recognition (CVPR) conference in June 2025 to support the challenge for the VQA task, and contains all 1,385 visual questions in the test dataset. Results on this partition will determine the challenge winners, which will be announced during the VizWiz Grand Challenge workshop hosted at CVPR. Each team can submit at most five results files over the length of the challenge and at most one result per day. The best scoring submitted result for each team will be selected as the team’s final entry for the competition.
- Test-standard: this partition is available to support algorithm evaluation year-round, and contains all 1,385 visual questions in the test dataset. Each team can submit at most five results files and at most one result per day. Each team can choose to share their results publicly or keep them private. When shared publicly, the best scoring submitted result will be published on the public leaderboard and will be selected as the team’s final entry for the competition.
Uploading Submissions to Evaluation Servers
To submit results, each team will first need to create a single account on EvalAI. On the platform, then click on the “Submit” tab in EvalAI, select the submission phase (“test”), select the results file (i.e., zip file) to upload, fill in required metadata about the method, and then click “Submit”. The evaluation server may take several minutes to process the results. To have the submission results appear on the public leaderboard, check the box under “Show on Leaderboard”.
To view the status of a submission, navigate on the EvalAI platform to the “My Submissions” tab and choose the phase to which the results file was uploaded (i.e., “test”). One of the following statuses should be shown: “Failed” or “Finished”. If the status is “Failed”, please check the “Stderr File” for the submission to troubleshoot. If the status is “Finished”, the evaluation successfully completed and the evaluation results can be downloaded. To do so, select “Result File” to retrieve the aggregated score for the submission phase used (i.e., “test”).
Submission Results Formats
Using the following JSON formats to submit results for the task. A naive baseline that always predicts one label (all samples share single grounding) can be found here.
‘Task 1: Single Answer Grounding Challenge
results = [result]
result = {
"question_id": string, # e.g., 'VizWiz_test_000000020000.jpg' for VizWiz image, "249549029" for VQA image
"single_grounding": float # confidence score, 0: multiple, 1: single
}
Leaderboards
The Leaderboard page for the challenge can be found here.
Rules
- Teams are allowed to use external data to train their algorithms. The only exception is that teams are not allowed to use any annotations of the test dataset.
- Members of the same team are not allowed to create multiple accounts for a single project to submit more than the maximum number of submissions permitted per team on the test-challenge and test-standard datasets. The only exception is if the person is part of a team that is publishing more than one paper describing unrelated methods.
Publication
- VQA Therapy: Exploring Answer Differences by Visually Grounding Answers
Chongyan Chen, Samreen Anjum, and Danna Gurari. IEEE International Conference on Computer Vision (ICCV) 2023.
Contact Us
For any questions, comments, or feedback, please send them to Everley Tseng at Yu-Yun.Tseng@colorado.edu Chongyan Chen at chongyanchen_hci@utexas.edu.